
Trong bài viết này, bạn sẽ tìm hiểu cách bộ nhớ của AI Agent hoạt động thông qua working memory (bộ nhớ làm việc), external memory (bộ nhớ bên ngoài) và scalable memory architectures (kiến trúc bộ nhớ có thể mở rộng) để xây dựng các agent ngày càng thông minh hơn theo thời gian.
Các nội dung sẽ đề cập gồm:
- Vấn đề về bộ nhớ trong các AI Agent dựa trên mô hình ngôn ngữ lớn (LLM) vốn không tự lưu trạng thái.
- Cách các loại bộ nhớ như in-context memory, episodic memory, semantic memory và procedural memory hỗ trợ hành vi của agent.
- Cách retrieval (truy xuất dữ liệu), ghi nhớ mới, xử lý việc quên dần theo thời gian và đồng bộ nhiều agent giúp hệ thống bộ nhớ hoạt động hiệu quả ở quy mô lớn.
Giới thiệu
Một AI Agent không có trạng thái (stateless) sẽ không nhớ những lần làm việc trước đó. Mỗi yêu cầu mới đều bắt đầu lại từ đầu. Điều này phù hợp với các tác vụ riêng lẻ, nhưng sẽ trở thành vấn đề khi agent cần theo dõi quyết định đã đưa ra, nhớ sở thích của người dùng hoặc tiếp tục công việc còn dang dở.
Thách thức nằm ở chỗ bộ nhớ của AI Agent không chỉ là một thứ duy nhất, mà là tập hợp của nhiều cơ chế khác nhau, mỗi cơ chế phục vụ một mục đích riêng. Các cơ chế này cũng hoạt động ở những mốc thời gian khác nhau có loại chỉ dùng trong một cuộc trò chuyện, có loại được lưu trữ lâu dài. Cách bạn kết hợp chúng sẽ quyết định agent có còn hữu ích qua nhiều lần sử dụng hay không.
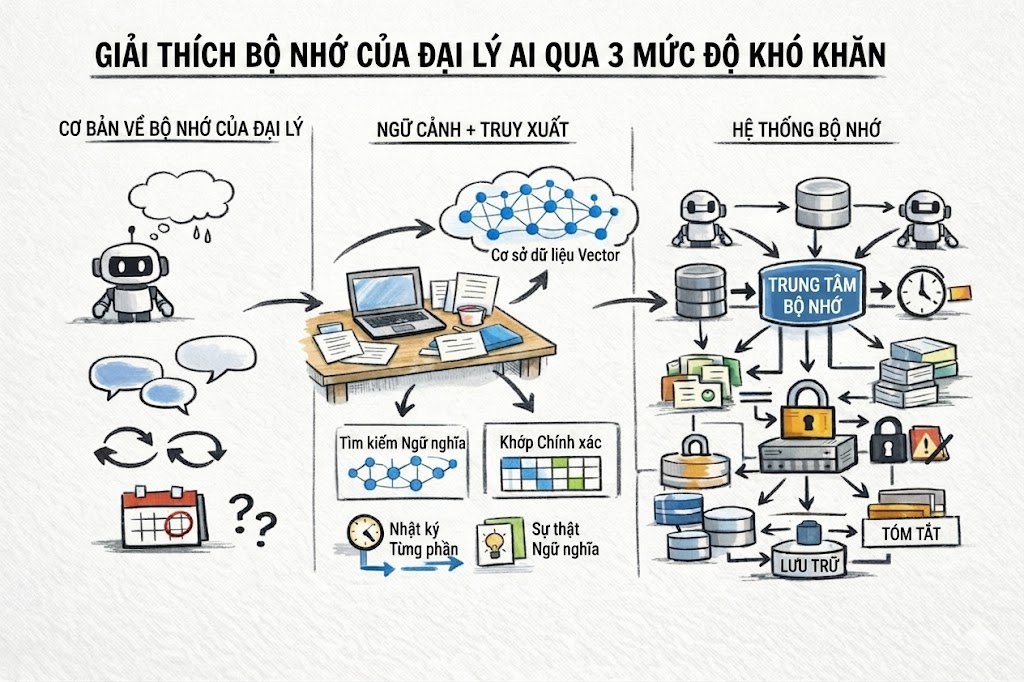
Bài viết này sẽ giải thích bộ nhớ của AI Agent theo 3 cấp độ: bộ nhớ có ý nghĩa gì với agent và vì sao nó khó xây dựng, cách các loại bộ nhớ chính hoạt động trong thực tế, và cuối cùng là các mô hình kiến trúc cùng chiến lược truy xuất giúp tạo ra bộ nhớ lâu dài, đáng tin cậy ở quy mô lớn.
Cấp độ 1: Hiểu vấn đề bộ nhớ trong AI Agent
Một mô hình ngôn ngữ lớn (LLM) không có trạng thái lưu trữ lâu dài. Mỗi lần gọi API đều là một phiên làm việc mới: mô hình nhận một khối văn bản (context window), xử lý, trả về phản hồi rồi không giữ lại gì sau đó. Không có “kho dữ liệu bên trong” nào được cập nhật giữa các lần gọi.
Điều này ổn khi chỉ dùng để trả lời một câu hỏi đơn lẻ. Nhưng nó trở thành vấn đề cốt lõi với những hệ thống mang tính agent tức là hệ thống cần thực hiện nhiều bước, học từ phản hồi hoặc phối hợp công việc qua nhiều phiên làm việc khác nhau.
Bốn câu hỏi sau sẽ giúp thấy rõ vấn đề bộ nhớ:
- Điều gì đã xảy ra trước đó?
Một agent đặt lịch cần biết lịch nào đã có sẵn. Nếu không nhớ, nó có thể đặt trùng lịch. - Người dùng này muốn gì?
Một trợ lý viết nội dung nếu không nhớ giọng văn và phong cách bạn thích sẽ luôn quay về cách viết chung chung ở mỗi phiên mới. - Agent đã thử những gì rồi?
Một research agent nếu không nhớ các truy vấn tìm kiếm thất bại trước đó sẽ tiếp tục lặp lại những hướng đi không hiệu quả. - Agent đã tích lũy được những thông tin nào?
Nếu trong lúc làm việc agent phát hiện thiếu một file quan trọng, nó cần ghi nhớ điều đó và đưa vào các bước xử lý tiếp theo.
Vấn đề bộ nhớ chính là làm sao để một hệ thống vốn không có trạng thái có thể hoạt động như thể nó sở hữu kiến thức lâu dài, có thể truy vấn và sử dụng lại về những gì đã xảy ra trong quá khứ.
Cấp độ 2: Các loại bộ nhớ của AI Agent
In-Context Memory hoặc Working Memory
Đây là hình thức bộ nhớ đơn giản nhất: mọi thông tin đang có trong context window ở thời điểm hiện tại. Bao gồm lịch sử trò chuyện, kết quả từ các công cụ (tool calls), system prompt, tài liệu liên quan tất cả đều được truyền vào mô hình dưới dạng văn bản trong mỗi lần xử lý.
Cách này có ưu điểm là chính xác và ngay lập tức. Mô hình có thể suy luận trên toàn bộ thông tin trong context với độ tin cậy cao. Không cần bước truy xuất dữ liệu, không có phỏng đoán, và không lo lấy nhầm thông tin.
Giới hạn lớn nhất là kích thước context window. Các mô hình hiện nay hỗ trợ khoảng 128K đến 1 triệu token, nhưng chi phí và thời gian phản hồi sẽ tăng theo độ dài dữ liệu. Vì vậy, bạn không thể chỉ đưa tất cả mọi thứ vào rồi xem như đã giải quyết xong.
Trong thực tế, in-context memory hoạt động tốt nhất cho trạng thái hiện tại của tác vụ, chẳng hạn như:
- Cuộc trò chuyện đang diễn ra
- Kết quả tool vừa tạo gần đây
- Tài liệu liên quan trực tiếp đến bước xử lý ngay lúc đó
External Memory
Đối với những thông tin quá lớn, quá cũ hoặc thay đổi liên tục nên không thể giữ thường xuyên trong context, AI Agent sẽ truy vấn từ một kho lưu trữ bên ngoài và chỉ lấy những gì liên quan khi cần. Đây chính là cách Retrieval-Augmented Generation (RAG) được áp dụng vào bộ nhớ của agent.
Có hai kiểu truy xuất chính, phục vụ hai nhu cầu khác nhau:
- Semantic search trên vector database: tìm những dữ liệu có ý nghĩa tương đồng với truy vấn hiện tại, ngay cả khi câu chữ không giống nhau.
- Exact lookup trên relational database hoặc key-value store: lấy chính xác dữ liệu có cấu trúc dựa trên thuộc tính cụ thể như sở thích người dùng, trạng thái tác vụ, quyết định trước đó hoặc hồ sơ của từng đối tượng.
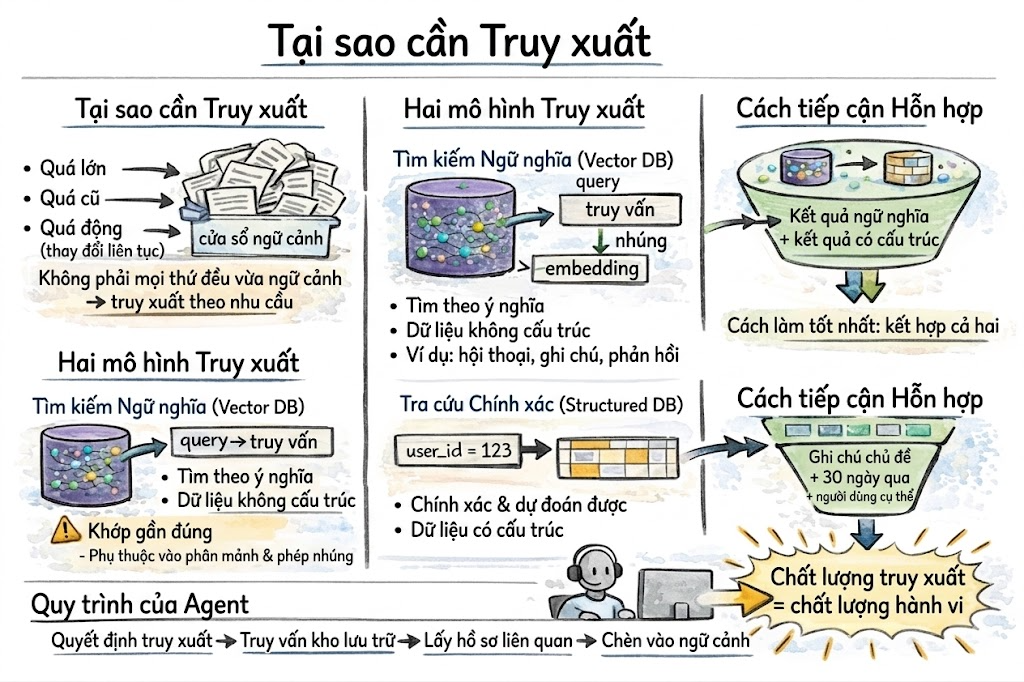
Trong thực tế, những hệ thống bộ nhớ AI Agent ổn định và hiệu quả nhất thường kết hợp cả hai cách trên: khi cần sẽ vừa chạy tìm kiếm bằng vector, vừa truy vấn dữ liệu có cấu trúc, sau đó gộp kết quả lại để sử dụng.
Cấp độ 3 tập trung vào việc đưa hệ thống bộ nhớ vào vận hành thực tế
Phần này vượt xa việc chỉ nói về các loại bộ nhớ cơ bản và đi vào những thách thức thực tế như:
- Cách tổ chức bộ nhớ chi tiết hơn theo từng lớp, từng nhóm thông tin
- Nên lưu dữ liệu gì và lưu vào thời điểm nào
- Làm sao truy xuất đúng dữ liệu một cách ổn định khi hệ thống mở rộng lớn
- Cách xử lý dữ liệu cũ, lỗi thời
- Cách quản lý khi có nhiều agent cùng ghi dữ liệu vào một hệ thống
Nói ngắn gọn, đây là phần nói về kiến trúc và chiến lược để đảm bảo bộ nhớ thực sự giúp AI Agent hoạt động tốt hơn theo thời gian.
Cấp độ 3: Kiến trúc bộ nhớ AI Agent ở quy mô lớn
Những gì cần được lưu trữ
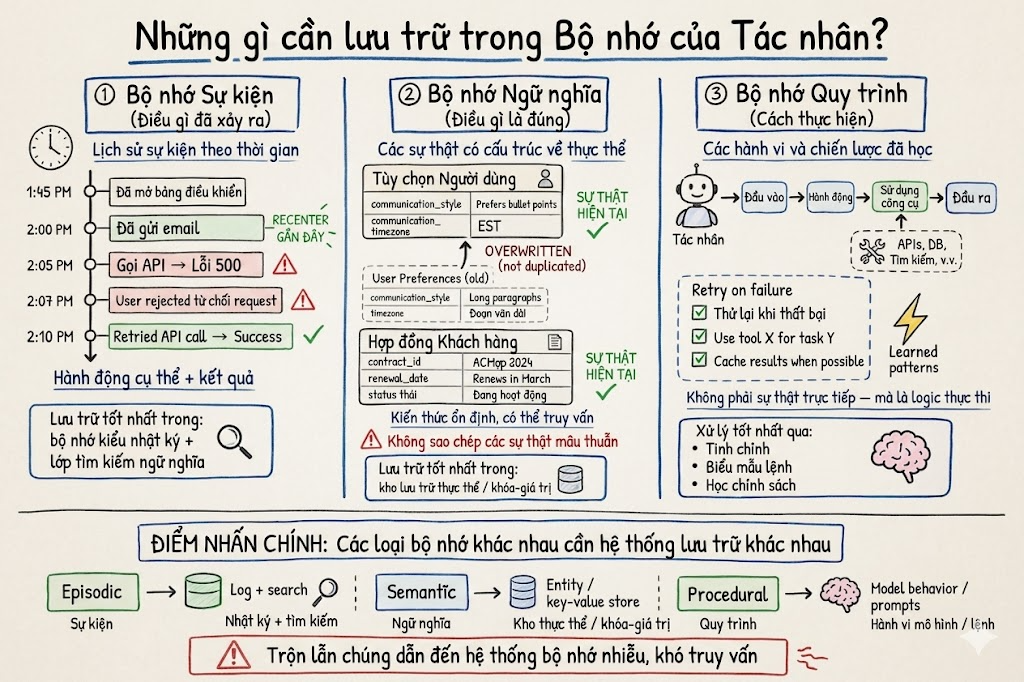
Không phải loại thông tin nào cũng nên được xử lý giống nhau, vì vậy cần xác định rõ bạn thực sự đang lưu trữ điều gì. Bộ nhớ của AI Agent thường được chia thành một vài nhóm chính:
- Episodic memory lưu lại những gì đã xảy ra: các sự kiện cụ thể, lần gọi công cụ (tool calls) và kết quả của chúng.
- Semantic memory lưu lại những gì là sự thật / thông tin đúng: các dữ kiện và sở thích được rút ra từ trải nghiệm trước đó.
- Procedural memory lưu lại cách thực hiện công việc: các quy trình hành động đã học được, chiến lược từng thành công và những lỗi đã biết để tránh lặp lại.
Ghi vào bộ nhớ: Khi nào và lưu những gì
Một AI Agent nếu ghi lại mọi token của mọi cuộc tương tác vào bộ nhớ sẽ nhanh chóng tạo ra rất nhiều dữ liệu rác khi hệ thống mở rộng. Vì vậy, bộ nhớ cần có sự chọn lọc. Dưới đây là hai cách phổ biến:
-
Tóm tắt cuối phiên làm việc:
Sau mỗi phiên, agent hoặc một bước tóm tắt riêng sẽ rút ra những thông tin quan trọng như dữ kiện nổi bật, quyết định đã đưa ra và kết quả đạt được, rồi lưu lại dưới dạng bản ghi ngắn gọn. -
Ghi nhớ khi có sự kiện kích hoạt:
Một số sự kiện sẽ tự động kích hoạt việc lưu bộ nhớ, ví dụ: người dùng chỉnh sửa/correct, nêu rõ sở thích cá nhân, hoàn thành nhiệm vụ hoặc xuất hiện lỗi.
Những gì không nên lưu
- Toàn bộ bản ghi hội thoại thô ở quy mô lớn
- Các bước suy luận trung gian không ảnh hưởng đến hành vi sau này
- Những dữ liệu trùng lặp với thông tin đã có sẵn
Truy xuất từ bộ nhớ: Lấy đúng ngữ cảnh cần thiết
Dưới đây là tổng quan về 3 chiến lược truy xuất phổ biến nhất:
- Vector similarity search: Hệ thống sẽ dùng embedding của ngữ cảnh hiện tại để tìm trong kho bộ nhớ và trả về top-K bản ghi có ý nghĩa gần nhất. Cách này nhanh, mang tính xấp xỉ và rất phù hợp với dữ liệu phi cấu trúc. Tuy nhiên, nó cần mô hình embedding và chỉ mục vector như HNSW hoặc IVF. Chất lượng kết quả phụ thuộc nhiều vào cách chia dữ liệu (chunking) và mô hình embedding được sử dụng.
- Structured query: Truy xuất dữ liệu dựa trên thuộc tính cụ thể như user ID, khoảng thời gian, tên đối tượng,… Cách này rất chính xác khi bạn biết rõ mình đang tìm gì. Tuy nhiên, nó không xử lý tốt các trường hợp ý nghĩa thay đổi hoặc diễn đạt khác nhau (semantic drift). Thường dùng với SQL hoặc key-value lookup.
- Hybrid retrieval:Kết hợp cả hai cách trên: chạy tìm kiếm vector và truy vấn có cấu trúc song song, sau đó gộp kết quả lại. Cách này hữu ích khi dữ liệu vừa có nội dung ngữ nghĩa vừa có metadata có cấu trúc. Ví dụ: tìm các bộ nhớ liên quan đến vấn đề thanh toán của người dùng này trong 30 ngày gần nhất.
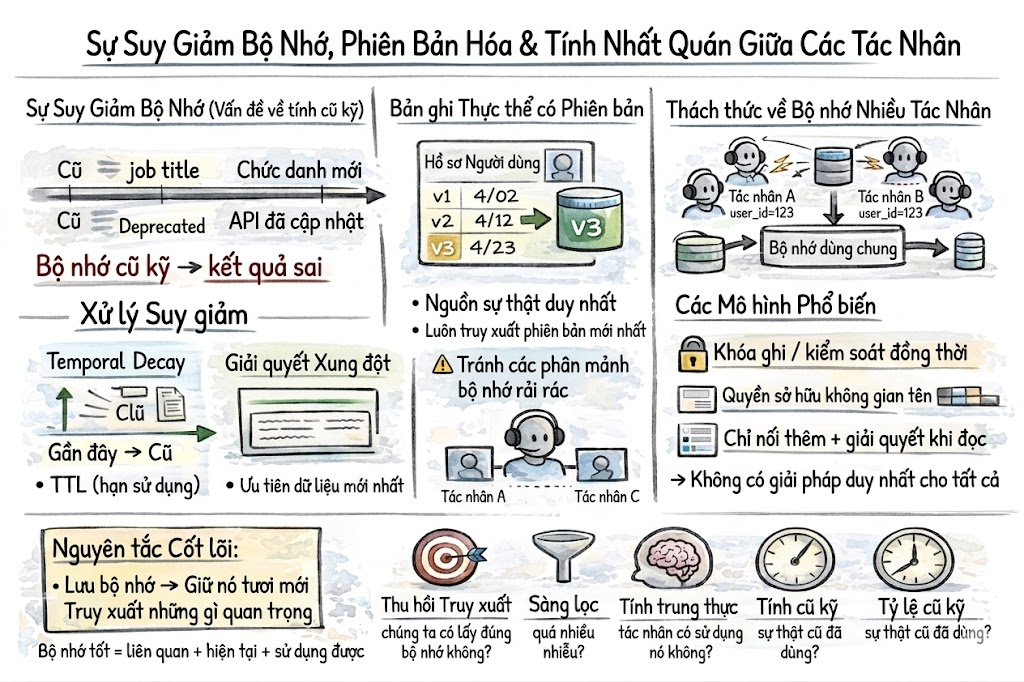
Memory Decay và Versioning
Bộ nhớ có thể trở nên lỗi thời theo thời gian. Ví dụ: chức danh công việc của người dùng thay đổi, hoặc một API endpoint trước đây đúng nhưng nay đã bị ngừng sử dụng. Nếu AI Agent tiếp tục dùng những thông tin cũ này, nó có thể gây ra lỗi ở các bước xử lý sau. Vì vậy, cần có cơ chế quản lý phù hợp. Dưới đây là hai cách quan trọng nhất:
- Temporal decay: Ưu tiên và đánh trọng số cao hơn cho những bộ nhớ mới, gần đây thay vì dữ liệu quá cũ.
- Versioned entity records:Duy trì kho dữ liệu có phiên bản cho từng đối tượng. Khi có cập nhật mới, giá trị mới sẽ ghi đè giá trị cũ nhưng vẫn lưu kèm mốc thời gian để theo dõi lịch sử thay đổi.
Multi-Agent Memory
Khi nhiều AI Agent cùng chia sẻ một hệ thống bộ nhớ, ví dụ một agent điều phối trung tâm và nhiều sub-agent chạy song song thì vấn đề khó nhất sẽ là đảm bảo tính nhất quán dữ liệu.
Dưới đây là những cách xử lý phổ biến:
- Central memory: Dùng cơ chế khóa (locking) hoặc optimistic concurrency để kiểm soát việc ghi dữ liệu, tránh xung đột khi nhiều agent cập nhật cùng lúc.
- Namespaces: Mỗi agent sẽ ghi dữ liệu vào không gian bộ nhớ riêng của mình, giúp giảm va chạm và dễ quản lý hơn.
- Append-only logs:Lưu lại toàn bộ thay đổi dưới dạng nhật ký, không xóa dữ liệu cũ. Khi đọc dữ liệu mới xử lý và giải quyết xung đột.
Không có giải pháp nào là tốt nhất cho mọi trường hợp. Cách chọn sẽ phụ thuộc vào cách các agent vận hành và chia sẻ trạng thái với nhau.
Đánh giá (Evaluation)
Hệ thống bộ nhớ thường lỗi một cách âm thầm. Agent có thể truy xuất sai dữ liệu, suy luận dựa trên thông tin sai đó và đưa ra một câu trả lời nghe rất hợp lý nhưng thực chất lại sai. Vì vậy, cần theo dõi những chỉ số quan trọng sau:
- Retrieval recall: Đo xem hệ thống có tìm ra đúng thông tin liên quan khi thông tin đó thực sự tồn tại hay không.
- Retrieval precision: Đo xem ngoài thông tin đúng, hệ thống có kéo theo quá nhiều dữ liệu rác hoặc không liên quan hay không.
- Faithfulness: Đo xem agent có thực sự sử dụng dữ liệu đã truy xuất trong quá trình suy luận hay không.
- Staleness rate:Đo tần suất agent sử dụng những thông tin đã cũ hoặc lỗi thời.
Nói ngắn gọn, quản lý bộ nhớ hiệu quả chính là lưu trữ thông tin sao cho luôn còn giá trị và có thể truy xuất đúng lúc khi cần.
Tổng kết
Bộ nhớ của AI Agent hoạt động giống như một ngăn xếp nhiều lớp. In-context memory giữ trạng thái làm việc hiện tại, còn external retrieval sẽ mang vào những lịch sử và dữ kiện liên quan khi cần.
Thách thức lớn nhất về mặt kỹ thuật nằm ở việc:
- Nên lưu lại thông tin gì
- Khi nào cần kích hoạt truy xuất dữ liệu
- Làm sao duy trì hệ thống bộ nhớ luôn sạch, hữu ích khi ngày càng mở rộng
Chúc bạn học tốt và xây dựng được nhiều AI Agent hiệu quả!
CyberSoft chuyên đào tạo Chuyên Gia Lập Trình, Công Nghệ, Thiết kế, AI theo dự án doanh nghiệp. Học theo dự án thực tế, học từ số zero đi làm, học nâng cấp kỹ năng toàn diện
Liên hệ chúng tôi để được tư vấn ngay nhé!



